Page 2 of 11
Posted: Sun Feb 11, 2007 4:44 pm
by Luminous
Here is something I did based on the link to the neb site from blablablee above. I input the gene letter sequence that was decoded and got this result.
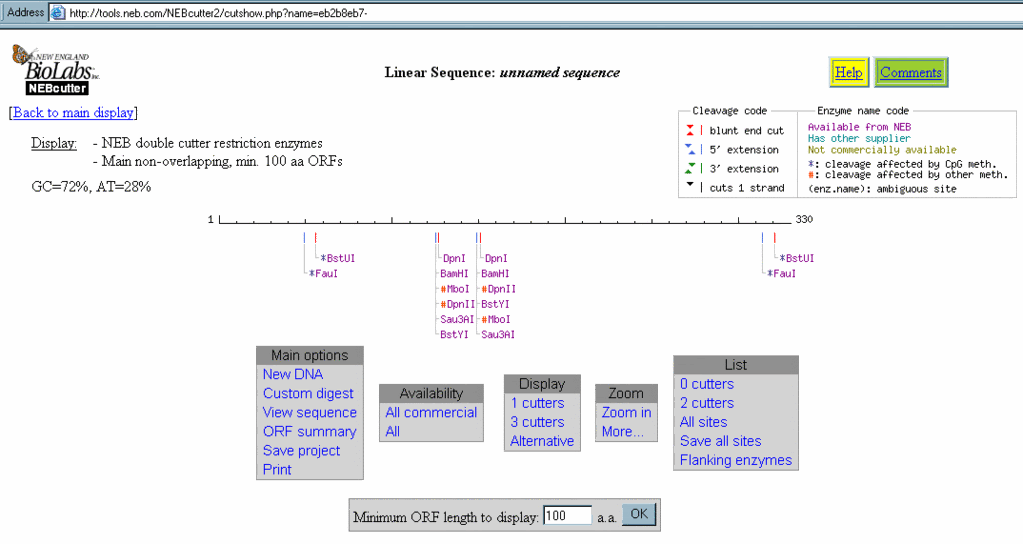
Then I clicked on 2 cutters (because double edged swords cut twice)under "list" and got this result :
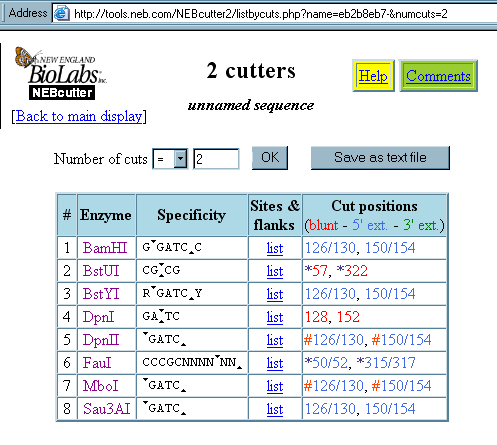
But all of this may be total nonsense, because I have no clue what I'm doing

Here is a new message I just received from Traveler:
We are looking for DNA, not RNA. The correct restriction enzyme, which is what we need to isolate may "Dash before your eyes""If you can count that"
I think this might be a reference to a couple of short sequences that "dash" by really fast in the video "catalyst(find him)".
One is of the briefcase that was sent to McPackage, the other is of someone in a dress shirt pouring something from one test tube into another - possibly the evidence of TravelerJ destroying "J1".
Anyway, I think if we count the dashes in these two sequences, it may point us to the answer we are looking for. Possibly it's morse code? Or maybe just a number we need.
I downloaded the footage so I could isolate the sequences and slow them down, making it easier to count the dashes, I'm not going to be able to get to it until later this evening.
On the subject of "WD, find him".
I'm wondering if that could that be a reference to "W. D. Hardt"? He's a real person though, not a character, so maybe not. But then again, possibly it is his research that we are supposed to be looking into.
Posted: Sun Feb 11, 2007 5:40 pm
by TOSG
BamHI is a very commonly used restriction enzyme - that might be a good candidate.
Let me know if you find anything in the video's flashes.
Posted: Mon Feb 12, 2007 3:09 am
by Luminous
Sorry I haven't posted the edited video yet. My editing program crashed, and I've spent the evening troubleshooting. No luck yet. Hopefully I'll have something by tomorrow.
Posted: Mon Feb 12, 2007 2:44 pm
by Brucker
I almost hate to suggest it, but since a restriction anzyme works on both sides of the DNA strand, it might be that the code is on the other side, which would be
CCTCACTCCCCTCGTCAACCCGG
TTCTACCGCCGGCGGCTCCCTGG
CCACCCGCTGCGCCCTCACTCCC
CTCGTCAACCCGGTTCTACCGCC
GGCGGCTCCCTGGCCACCCGCTG
CCCCCTCACTCCTAGGAAAAATAA
GAAGCTGAGTCCTAGGCCCCTCGT
CAACCCGGTTCTACCGCCGGCGG
CTCCCTGGCCACCCGCTGCCGCC
TCACTCCCCTCGTCAACCCGGTTC
TACCGCCGGCGGCTCCCTGGCCA
CCCGCTGCCCCTCACTCCCCTCGT
CAACCCGGTTCTACCGCCGGCGGC
TCCCTGGCCACCCGCTGCGCCCTCAC
Once again, not having a very full understanding of genetic coding principles, if this is the case, I'm not sure if you'd then also process the strand from right to left at your starting point?
Posted: Mon Feb 12, 2007 2:53 pm
by TOSG
Brucker wrote:
Once again, not having a very full understanding of genetic coding principles, if this is the case, I'm not sure if you'd then also process the strand from right to left at your starting point?
Sort of. What you would actually look at is the reverse complementary strand: it's the given sequence backwards, and with each base replaced by its pairing partner (G--->C; A--->T). There are programs that will make this switch automatically. In fact, the restriction analysis that Luminous posted takes into account both the given sequence and its complement. (EDIT: Actually, upon further investigation, it might not.)
Good thinking, though - it seems quite possible that this could be part of the puzzle.
Edit: I see what you're saying...yes, you would reverse the sequence.
Posted: Mon Feb 12, 2007 2:56 pm
by Brucker
Okay, and just for good measure, here's the list offset by one:
Code: Select all
GAG Glutamic acid
TGA STOP
GGG Glycine
GAG Glutamic acid
CAG Glutamine
TTG Leucine
GGC Glycine
CAA Glutamine
GAT Aspartic acid
GGC Glycine
GGC Glycine
CGC Arginine
CGA Arginine
GGG Glycine
ACC Threonine
GGT Glycine
GGG Glycine
CGA Arginine
CGC Arginine
GGG Glycine
AGT Serine
GAG Glutamic acid
GGG Glycine
AGC Serine
AGT Serine
TGG Tryptophan
GCC Alanine
AAG Lysine
ATG Methionine or START
GCG Alanine
GCC Alanine
GCC Alanine
GAG Glutamic acid
GGA Glycine
CCG Proline
GTG Valine
GGC Glycine
GAC Aspartic acid
GGG Glycine
GGA Glycine
GTG Valine
AGG Arginine
ATC Isoleucine
CTT Leucine
TTT Phenylalanine
ATT Isoleucine
CTT Leucine
CGA Arginine
CTC Leucine
AGG Arginine
ATC Isoleucine
CGG Arginine
GGA Glycine
GCA Alanine
GTT Valine
GGG Glycine
CCA Proline
AGA Arginine
TGG Tryptophan
CGG Arginine
CCG Proline
CCG Proline
AGG Arginine
GAC Aspartic acid
CGG Arginine
TGG Tryptophan
GCG Alanine
ACG Threonine
GCG Alanine
GAG Glutamic acid
TGA STOP
GGG Glycine
GAG Glutamic acid
CAG Glutamine
TTG Leucine
GGC Glycine
CAA Glutamine
GAT Aspartic acid
GGC Glycine
GGC Glycine
CGC Arginine
CGA Arginine
GGG Glycine
ACC Threonine
GGT Glycine
GGG Glycine
CGA Arginine
CGG Arginine
GGA Glycine
GTG Valine
AGG Arginine
GGA Glycine
GCA Alanine
GTT Valine
GGG Glycine
CCA Proline
AGA Arginine
TGG Tryptophan
CGG Arginine
CCG Proline
CCG Proline
AGG Arginine
GAC Aspartic acid
CGG Arginine
TGG Tryptophan
GCG Alanine
ACG Threonine
CGG Arginine
GAG Glutamic acid
...and offset by two:
Code: Select all
CODON Base
AGT Serine
GAG Glutamic acid
GGG Glycine
AGC Serine
AGT Serine
TGG Tryptophan
GCC Alanine
AAG Lysine
ATG Methionine or START
GCG Alanine
GCC Alanine
GCC Alanine
GAG Glutamic acid
GGA Glycine
CCG Proline
GTG Valine
GGC Glycine
GAC Aspartic acid
GCG Alanine
GGA Glycine
GTG Valine
AGG Arginine
GGA Glycine
GCA Alanine
GTT Valine
GGG Glycine
CCA Proline
AGA Arginine
TGG Tryptophan
CGG Arginine
CCG Proline
CCG Proline
AGG Arginine
GAC Aspartic acid
CGG Arginine
TGG Tryptophan
GCG Alanine
ACG Threonine
GGG Glycine
GAG Glutamic acid
TGA STOP
GGA Glycine
TCC Serine
TTT Phenylalanine
TTA Leucine
TTC Phenylalanine
TTC Phenylalanine
GAC Aspartic acid
TCA Serine
GGA Glycine
TCC Serine
GGG Glycine
GAG Glutamic acid
CAG Glutamine
TTG Leucine
GGC Glycine
CAA Glutamine
GAT Aspartic acid
GGC Glycine
GGC Glycine
CGC Arginine
CGA Arginine
GGG Glycine
ACC Threonine
GGT Glycine
GGG Glycine
CGA Arginine
CGG Arginine
CGG Arginine
AGT Serine
GAG Glutamic acid
GGG Glycine
AGC Serine
AGT Serine
TGG Tryptophan
GCC Alanine
AAG Lysine
ATG Methionine or START
GCG Alanine
GCC Alanine
GCC Alanine
GAG Glutamic acid
GGA Glycine
CCG Proline
GTG Valine
GGC Glycine
GAC Aspartic acid
GGG Glycine
GAG Glutamic acid
TGA STOP
GGG Glycine
GAG Glutamic acid
CAG Glutamine
TTG Leucine
GGC Glycine
CAA Glutamine
GAT Aspartic acid
GGC Glycine
GGC Glycine
CGC Arginine
CGA Arginine
GGG Glycine
ACC Threonine
GGT Glycine
GGG Glycine
CGA Arginine
CGC Arginine
GGG Glycine
AGT Serine
Posted: Mon Feb 12, 2007 3:00 pm
by Luminous
I'm still troubleshooting my editing program, so I don't yet have a clip to post, but I wanted to mention that in "History Lessons (Coded Rings)" it is pointed out that "the gene of interest is a 'Toxic' gene".
Posted: Mon Feb 12, 2007 3:03 pm
by kellylen
if i remember correctly from last semester about DNA, a DNA sequence usually completely ends at a series of As. like A LOT of As.
Posted: Mon Feb 12, 2007 3:04 pm
by TOSG
kellylen wrote:if i remember correctly from last semester about DNA, a DNA sequence usually completely ends at a series of As. like A LOT of As.
You're thinking of (human) mRNA.
Posted: Mon Feb 12, 2007 3:07 pm
by TOSG
This is interesting: the following motif "GGAGTGAGGGGAGCAGTTGGGCCAAGATGGCGGCCGCCGAGGGACCGGTGGGCGACG" repeats 4 times within the sequence.
Posted: Mon Feb 12, 2007 3:25 pm
by TOSG
I think I'm getting somewhere here... when I cut out the portion of the gene that would be removed by using BamHI (a double-cutting restriction enzyme), nearly all that remains is the 4 repeats of the sequence that I gave above. This repeat comes directly from human nucleoporin DNA. The sequence that would be cut out by BamHI has no significant homology with any other known gene.
Thus, it seems clear that the sequence is composed of two different elements: a repeating sequence from human nucleoporin DNA, and an insert by TravelerJ. I think that it's likely that one of these is significant, and the other is meant to be disregarded.
What do you guys make of this? What, exactly, do you think we're trying to find?
(If someone is willing to bring me up to speed on AIM or somesuch, send me a PM).
Posted: Mon Feb 12, 2007 3:41 pm
by Brucker
TOSG wrote:This is interesting: the following motif "GGAGTGAGGGGAGCAGTTGGGCCAAGATGGCGGCCGCCGAGGGACCGGTGGGCGACG" repeats 4 times within the sequence.
It's bound to be significant. FYI, the reverse compliment is:
Code: Select all
CCT Proline
CAC Histidine
TCC Serine
CCT Proline
CGT Arginine
CAA Glutamine
CCC Proline
GGT Glycine
TCT Serine
ACC Threonine
GCC Alanine
GGC Glycine
GGC Glycine
TCC Serine
CTG Leucine
GCC Alanine
ACC Threonine
CGC Arginine
TGC Cysteine
Posted: Mon Feb 12, 2007 4:03 pm
by TOSG
Brucker: the reverse complement goes from right-to-left, not left-to-right.
I actually tend to think that the important part isn't the repeating unit, but rather what TravelerJ inserted into the middle (flanked by BamHI cut sites). I'm a bit confused, though, about where to go from here - there's some stuff that I could play around with, but if anyone has any clear ideas what we might be looking for (a word (or tinyurl) coded into the one-letter abbreviated protein sequence? That's about the only thing that comes to my mind), then don't be shy.
Posted: Mon Feb 12, 2007 4:11 pm
by Luminous
TOSG wrote:
What do you guys make of this? What, exactly, do you think we're trying to find?
I think we are trying to find a 5'3' restriction enzyme (DNA, not RNA) that is a "double edged sword" (in otherwords it cuts twice). That it is a "Toxic Gene", and that it can somehow be identified by counting the number of flashes in the two short clips from the most recent video.
I don't know much about genetics, so I'm lost in how to take these clues and put them to any practical use. There are more clues in the various videos as well. I'm working on compiling a list of everything I think might be a clue.
I think we are also looking for WD - someone who has more information about what went down at FacilityJ than Traveler does.
We have a profile of him (shown at the end of the second Catalyst video). Who is he and how do we find him? My research came up with a well published geneticist named W.D. Hardt. I don't know if he's the guy we're looking for or not. He's a real guy, not a fictional character. Maybe Traveler J is trying to point us toward Hardt's research.
Posted: Mon Feb 12, 2007 4:23 pm
by TOSG
Luminous: Cool, I'm looking forward to that list.
Just so that everyone knows, a restriction enzyme is a protein that cuts a DNA sequence in a specific location. The terms "5'3'," and "toxic gene" almost certainly refer to the DNA itself. "Double-edged sword" almost certainly refers to the restriction enzyme that is operating upon the DNA.
WD Hardt appears to be a "real-life" German microbiologist/immunologist. His work, while apparently fairly impressive (just judging from a list of his published articles and which journals they went into), doesn't seem immediatly noteworthy. What led you to his name?